
Implementing a Scalable Architecture for e-Commerce
Implementing a Scalable Archicture for e-Commerce
With the widespread adoption of the World Wide Web as a channel for exchanging information and conducting business transactions, the demand for developing scalable, distributed applications using web technology is increasing. Other trends in the business community, such as the increasing frequency of business mergers and spin-offs, are driving demands for more sophisticated systems integration technologies and flexible system architectures. An organization's success often depends on its ability to adapt quickly to changing business conditions.
Now, more than ever, IT organizations are being asked to deliver new or updated application functionality under shorter time constraints while still addressing ongoing requirements for system reliability, scalability, integrity and performance. As a result, development organizations are constantly looking for new development technologies that will help them be more responsive to changing application requirements while minimizing development and maintenance costs.
Many of today's IT organizations have been shifting their strategic focus onto the design of multi-tier application architectures that place greater emphasis on the development of reusable distributed object services in the middle tier. Multi-tier application architectures offer greater scalability, reusability, flexibility and easier maintenance, which are all essential requirements of any electronic commerce application.
This paper explains the concept of multi-tiered application architectures and the advantages they have to offer. Then, the paper focuses in on the requirements of one particular tier, which we call the data services layer. Finally, the paper describes the architecture of a data services layer as it would be implemented using the ONTOS e-COM Framework.
Why Design Multi-Tier Architectures?
Because multi-tier architectures are component-based, they provide the most flexibility for building, deploying and maintaining applications. The application design partitions the presentation logic, business logic and data access logic into components, which can be deployed within the physical hardware and software infrastructure that connects the desktop system to the mainframe. Component-based software development technology enables application developers to create and test individual components long before the entire system is deployed and it simplifies maintenance efforts after the components are deployed.
About Multi-Tier Software Architectures
The term, three-tier refers to the separation of application services into three logically different service categories.
Presentation Services
Contains the logic that presents information to a user and obtains input from that user. The presentation logic generally provides options that allow the user to navigate to different parts of the application, and it manipulates the input and output of graphics and information on the display device. Often, presentation components also perform some simple validation of user input.
A benefit of separating Presentation Services from Business Services is user interface flexibility so that multiple interfaces, from web browsers to desktop or handheld devices, can access the application.
Business Services
Contains the application logic that governs the execution of business rules and processes that are invoked either by a presentation component when a user requests an option, or by another business component. Business components also perform data manipulation that transforms the data to a level of abstraction that is meaningful to the Presentation Services layer. Providing a separate business services layer improves both manageability and scalability.
Data Access Services
Contains the logic that interfaces either with a data storage system, such as a relational database or a hierarchical file system, or with some other type of external data source, such as a data stream or an external application system. Data access methods are generally invoked by a business services layer, although in simple applications they may be invoked directly by a presentation component.
The term, multi-tier, implies that there is additional layering within at least one of the three major divisions, usually in the business application services tier. In the example of a multi-tier application architecture shown below, you can see the three logical tiers, as well as the additional layering within each tier.
The Multi-Tier Software Architecture Model
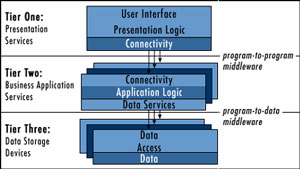
In a multi-tier architecture, application components can be shared by any number of application systems and are developed using the best tool for the job. The application components can be deployed across one or more physical systems. They communicate with each other using an abstract interface that makes the underlying functionality available to other components.
An abstract interface hides the actual application logic performed within the application object. The abstract interface allows the object to be viewed as a black box by the outside world. More to the point, the application logic within the object can be modified or replaced without impacting the other application objects that interface with it. If the component interface does not change, no modifications need to be made in any other component.
Advantages of a Multi-Tier Architecture
Well-designed multi-tier architectures offer the following advantages:
Scalability and Performance
The different components of a multi-tiered application are typically designed to communicate with each other over a network, so they can be distributed. Since the components are not confined to a single processor, applications can not only be scaled, but also tuned through application monitoring and load balancing. If any machine in use becomes overloaded, you have the options of upgrading to a larger machine; reconfiguring the component distribution; or replicating the overloaded server components on another machine.
Object Reuse
The advantages of a multi-tiered environment extend beyond the life cycle of a single application. In fact, what is being built is not just an application: it is a collection of client and server modules that communicate through standardized, abstract interfaces. When combined, the components behave like an integrated application system. Each module is a shareable, reusable object that can be used in multiple application systems. For example, three or four different front-end applications may call on the same set of business objects.
Faster Time-to-Market
A well-designed multi-tier architecture provides the ability to rapidly develop and deploy applications. Since application functions are isolated within relatively small application components, application logic can be developed and tested as independent units before integrating and deploying the whole application system. Since components can be tested as soon as they're complete, the testing process begins sooner, which gets the application out to users faster. Breaking a development project into a number of smaller component development efforts also reduces the risk of project failure.
Easier Maintenance
Component-based development also makes it easier to modify or update individual application components without having to update the entire application. For example, legacy systems on the back-end can be modified or replaced without significantly impacting the front-end application user interface.
More Effective Use of Data and Networks
The application logic is no longer tied directly to the database structures or a particular DBMS. Individual application objects work with their own encapsulated data structures which may correspond to a data base structure, or might be a data structure derived from a number of different data sources. When application objects communicate, they only need to send the data parameters as specified in the abstract interface rather than as entire database records, thereby reducing network traffic. The data access objects are the only application components that interface directly with the databases. This independence allows development organizations to react better to either business or technological changes.
Higher Developer Productivity through Specialization
With two-tiered methodologies, each developer had to know how to develop all aspects of an application, including presentation, business, and data access logic. In multi-tiered application development, each developer only needs to understand the component they are working on and how it interfaces with other components. So, developers who have expertise in user interface design can concentrate on developing presentation components; they require very little knowledge of the underlying data services infrastructure. On the back end, database analysts can concentrate on improving the performance of the data storage systems without being concerned about how the data is presented to an end user. In-between, business analysts can focus on systematizing the business processes and rules that make the business run smoothly.
Simplifying Development through Abstraction of Interfaces
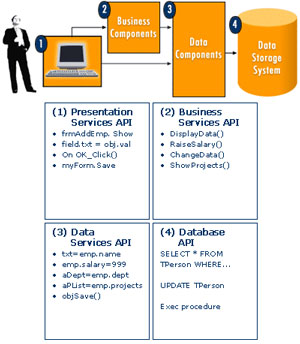
One of the goals in designing multi-tier application architectures is to have each layer present an interface that is expressed at an appropriate level of abstraction for the service provided. As you move out towards the user, the programming interfaces present higher levels of abstraction that are increasingly more meaningful to humans. As you move closer to the database, you see lower-level interfaces that expose more and more of the underlying system architecture that are more closely represent the kind of detailed instructions that machines require.
The presentation services are typically implemented by calling high-level functions on business application service components, which encapsulate the business processes and rules for your enterprise. The business components call on the data component interfaces to persist object data or to gain relatively transparent access data stored in your corporate database. The business components may need to make several calls to the data services interface in order to execute a single business method. The data services components, in turn, may need to make several calls to the database interface in order to execute a single operation.
Challenges of Multi-Tier Architectures
The idea of multi-tier architectures has been around for a while and there are many convincing arguments in favor of using multi-tier architectures. So, why don't we see more implementations of multi-tier architectures? The answer lies in understanding the challenges you are likely to encounter when designing and implementing large-scale multi-user distributed systems.
Part of the challenge lies in finding a way to provide the infrastructure and operating system services that are required in the middle tier of a distributed computing environment. The environment of Windows NT, Microsoft Transaction Services (MTS) and DCOM provide a comprehensive set of required business application services. These services include:
- Resource Sharing - connections, threads, memory, etc. (MTS/NT)
- Distributed Communication Services (MTS/NT/DCOM)
- Security Services (NT/MTS)
- Transaction Management (MTS)
- Messaging Services (MSMQ)
- Scheduling Services
- Catalog/Repository Services
The Data Services Implementation Challenge
Among the remaining technical challenges, one of the most significant is the mismatch that exists between any business application object model and any production database that holds corporate data used by legacy applications. Add to that the complexity of storing data in more than one database.
In a multi-tier application architecture, you can hide that complexity from your regular desktop application developers, but you still need to implement the interface. Industry analysts have pointed out that implementing the data services layer in a large-scale new application development project can consume 40-70% of your development resources. Depending on the quality of the design, testing those interfaces can consume a similar proportion of your testing resources.
A few of the hard realities that make it so costly and time-consuming to create and maintain a data services layer include:
- Denormalized databases are the norm, making it difficult to derive a logical object model from existing databases
- Object models and data models are driven by different priorities
- Database administrators and object model designers often work in different places, with different objectives in mind
- Coding a data services layer by hand can be an insurmountable task
- Data models and object models change constantly, often resulting in exorbitant data services layer maintenance costs if the data components are coded directly to the database structure.
- Expertise in developing a data services layer in today's tight labor market is hard to find
Requirements for the Data Services Layer
Based on many years of experience working with customers on the design and implementation of object-oriented applications that require access to corporate data stores, ONTOS has developed a deep understanding of the requirements for a data services layer. ONTOS defines those requirements as follows:
- Flexible data mapping
- Dynamic SQL command optimization
- Data component interface
- Access to DBMS processing
- Transparent navigation of associations
- Performance optimization
- Business and database transaction support and coordination
- Flexible, scalable deployment
- Component security
- Manageable administration and maintenance
Flexible Data Mapping
How does data get from the object model to the database and back? The ONTOS solution supports many complex types of mappings, including:
- Single class to single table
- Single class to multiple tables
- Multiple classes to single table
- Single class to tables in multiple databases
- Single-inherited classes to single or multiple tables
- Mapping to denormalized data
Flexible mapping capabilities can save the C++, Java, or Visual Basic developer from having to worry about relational data structures, while allowing the database administrator to exercise his or her expertise in the management and tuning of the database environment.
However, creating the initial mapping is not the entire picture of the mapping requirements. Developers must have the means to update data components and their associated mapping information whenever either the object model or database changes.
An Intuitive Component Programming Interface
In the past, developers were required to write applications in the language of the database to be accessed. This issue, often a costly and time-consuming problem, is addressed by the Data Component API. By allowing developers to work within their preferred development environment, C++, Java, and Visual Basic developers can all develop applications without having to know SQL syntax and without restrictions caused by 'foreign data' in the underlying data structures.
Navigational Transparency
The ONTOS e-COM Framework enables application developers to design object models without worrying about underlying relational data structures. The ONTOS technology supports the definition of objects that define inheritance, reference, and aggregated relationships that may not be directly represented in the database. The generated Data Component API allows programmers to navigate object relationships, without having to know how relationships are defined in the database.
Transaction Support and Coordination
Application-level transactions can be created to run as required by the business needs without worrying about underlying database transactions. ONTOS data component services, by leveraging the capabilities of MTS, provide transparent rollback and recovery of transactions, even when accessing multiple data sources.
Component Security Support
In a multi-tier environment, there are often different security implementations within the various layers. Every database has a set of authorized accounts, which may or may not correspond to the user ID of the process accessing the database. The business application level may be similarly independent and protected based on its own security model.
To make coordination of these various security models manageable in environments where there are hundreds of users, MTS offers the option to define user-based or role-based security. ONTOS has extended the MTS security support by providing a way to integrate your application security model with your database security models. Access to data can then be granted:
- Using a default database user account
- Based on the identity of the process requesting access
- By user membership in an MTS role
- Using a user ID and password passed to the Data Component Server at run time
Dynamic SQL Generation and Optimization
The ONTOS Data Component Server uses the mapping information that developers provide in a mapping model to dynamically generate the SQL code needed to access the database. The data access behavior can be optimized, both in the mapping model, and through efficient use of the generated Data Component API. Additional optimization is provided by the core data services components. The generated data components:
- Optimize reading of data
- Navigate database relationships using both logical and physical joins
- Optimize writing of all necessary data for inserts and updates, taking redundant data stores and triggers into consideration
- Use database constraints and cascading deletes when deleting data
- Call stored procedures
- Set locks appropriately for concurrent data access
- Work with the security information defined in the mapping model
Access to DBMS Processing Capabilities
The generated data components take advantage of powerful database features, such as triggers, cascading deletes, locking, stored procedures, and database exception handling. Also, multiple applications can be implemented to concurrently access the database, while the data components preserve the integrity of the data.
Performance Optimization
The ONTOS Data Component Server automatically optimizes performance by:
- Defining different access behavior for read versus insert, update and delete operations
- Doing "lazy reads" (not reading data until it is used)
- Optimizing attribute retrieval for "just-in-time" population of object data
- Using a local data cache
- Modifying attribute retrieval behavior so only needed attributes are retrieved
- Customizing the definition of add, update, and remove operations
Flexible, Scalable Deployment through MTS
By employing MTS and DCOM technology, the ONTOS technology provides support for deploying scalable applications in a distributed computing environment. DCOM supports communication and coordination between distributed components, while MTS provides the transaction management and resource pooling services that are required for multi-user support.
Manageable Data Component Maintenance
They say the only constant you can count on is the fact that things change. Your application object models and database models must change continuously to keep pace with the changes in your business. The increasing frequency of these changes is placing greater importance on the maintainability of applications. The ONTOS e-COM Framework was designed to make it easy for you to incorporate object model changes and database schema changes into your mapping model and generate updated Data Components, making it possible to keep your data services layer in step with the changes in your business requirements.
The ONTOS e-COM Framework for a COM Data Services Layer
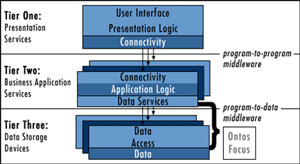
Earlier in this paper, the concept of a multi-tier architecture was discussed and a model was provided. An update to this model below identifies the focus of ONTOS for implementing the COM-based data services. The following diagram illustrates the value that ONTOS provides for solving the problem created by the gap between an object-oriented business application and corporate data stores.
ONTOS Value Added to the Multi-Tier Architecture Model
The ONTOS e-COM Framework enables developers to generate a COM-based data services layer that runs within a multi-tier application architecture. The data services layer is designed to execute within the larger framework of the Windows DNA architecture.
The ONTOS Data Component Server Architecture
As part of the development process, ONTOS Development Tool generates:
- One data component DLL for each package in the associated application object model
- One mapping information file for the mapping model from which the data components are generated
The data components and mapping information file are deployed, along with the ONTOS Data Services Components, on a Windows NT server running MTS. The layers within the ONTOS data services architecture are shown in the diagram below.
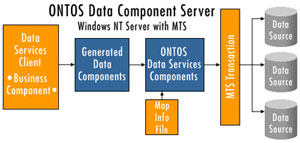
The following topics describe each of the components in the ONTOS Data Component Server architecture.
Data Services Client
In the ONTOS Data Component Server architecture, any software component or process that calls a data component server interface is a data services client. In many cases, the data services clients are business components that use data components to access corporate data that is required to execute business processes. Data services clients may also use the data components to implement persistence for objects that need to be accessible to other processes. Within a COM-based architecture, you can implement data services clients using any language that supports COM, such as Visual Basic, Visual C++, or Visual J++. The ONTOS Data Component Server architecture presents no requirement for the data services client to run under MTS. However, the client must be configured to have either local or remote to access the generated data components. If the client requires access to the ONTOS Metadata API, then the client must also be configured to access the components of the ONTOS Data Component Manager, which is one of the core data services.
Generated Data Components
The generated data components must be installed in an MTS package on a Windows NT server, which must be the same physical server where the ONTOS Data Services Components are deployed. The data components provide a simple COM interface that enables data services clients to access corporate data stores through an application-specific component interface. Developers do not need to know the underlying database organization in order to use the API presented by the generated data components. The generated data components are instantiated as COM objects that maintain their state in a local data cache until the client releases them.
ONTOS Data Services Components
The ONTOS Data Services Components consist of two COM servers and a set of common services libraries that support them.
- Data Component Manager - a COM server that provides common data services to the generated data components and presents a metadata interface that provides data services clients with read-only access to the metadata that is stored in the mapping information file. The Data Component Manager also holds the component that works with the Microsoft Distributed Transaction Coordinator (MS DTC) to coordinate transactions across the data sources to which the data components are mapped. The Data Component Manager consists of several COM components that must be configured in an MTS package on the same server as the generated data components.
- Data Access Manager - a COM server that works with MTS to open and manage database connections and issues SQL commands to the appropriate data sources when the generated components require access to the data sources to which they are mapped. These are stateless MTS components that must be configured in an MTS package.
- Data Services Libraries - a set of C++ libraries that provide a variety of support services for the Data Component Manager, which includes reading the mapping information file.
ONTOS-generated Mapping Information
The mapping information file is a binary file generated by the ONTOS Development Tool. It stores the specific object-to-data mapping information for a given mapping model. There is one mapping information file per mapping model. The Mapping Information is statically loaded into memory once when the Data Component Server is started and is available to any client as long as the server process is running. The mapping information is used to dynamically generate the SQL commands that the Data Component Server uses to access the appropriate rows in the database. The mapping information file must be deployed on the same MTS server as the ONTOS Data Services Components.
Corporate Data Stores
ONTOS-generated Data Components can access one or more corporate data stores through any OLE DB provider The data store must provide an interface (ODBC or native OLE DB) that has support for MTS transaction coordination. When a business application object invokes the data services interface, an instance of an ONTOS data object is instantiated on the Data Component Server. ONTOS data objects have methods for using the generated mapping information to retrieve the state of the object from the database, and to save changes to the database. When an object is instantiated, its attributes may either be populated by the caller, in which case the object would be saved as a new object, or the state of an existing object can be retrieved from the database.
Summary
Multi-tier software architectures are the preferred approach for developing scalable, high-performance, distributed applications. Microsoft's COM platform provides a complete set of the necessary business services. The ONTOS technology provides the object-to-relational link for capturing your object and data models, creating a mapping between the two models, and then generating data components. Multi-tier application development based upon Microsoft's COM platform and ONTOS' e-COM Framework enables you to create your data services layer and successfully deploy your applications. The information contained in this document represents the current view of ONTOS, Inc., on the issues discussed as of the date of this publication. Because ONTOS must respond to changing market conditions, this document should not be interpreted to be a commitment on the part of ONTOS, and ONTOS cannot guarantee the accuracy of any information presented after the date of publication.